


Nuclear localization sequence potentially found in Wuhan Hu 1 version of SARS CoV 2 Glycoprotein, and possible corroboration of HIV glycoprotein homology

I used to disseminate this type of information to various independent research organizations that I used to volunteer for, however, I have since left some of those groups for greener pastures. Also, the topics covered here are too complicated and nuanced for most of my peers to understand in that context, so perhaps posting here will increase the likelihood that people who understand these implications get to read them. This article will not be crafted very well for lay people however, as it is mostly for myself, and not intended as a presentable creation by me that I would seek to earn revenue off of. This is simply my research, and is something I have done since the start of the pandemic. It has helped me grow my fundamental knowledge to be equivalent with some of the best scientists (and no, I don't mean the ones who adhere to the narrative) and is something I see as a moral duty, i.e. to do what I can to push back against the ever expanding hand of the biosecurity control grid. My math skills and human anatomy are still rather lacking, but it's irrelevant in this context, as I don't need much skill in those fields to understand the following material
A nuclear localization signal, or sequence, is: "An amino acid sequence that 'tags' a protein for import into the cell nucleus by nuclear transport." A preprint has recently surfaced showing that part of the furin cleavage site, also has the potiential to double as an NLS. https://en.wikipedia.org/wiki/Nuclear_localization_sequence

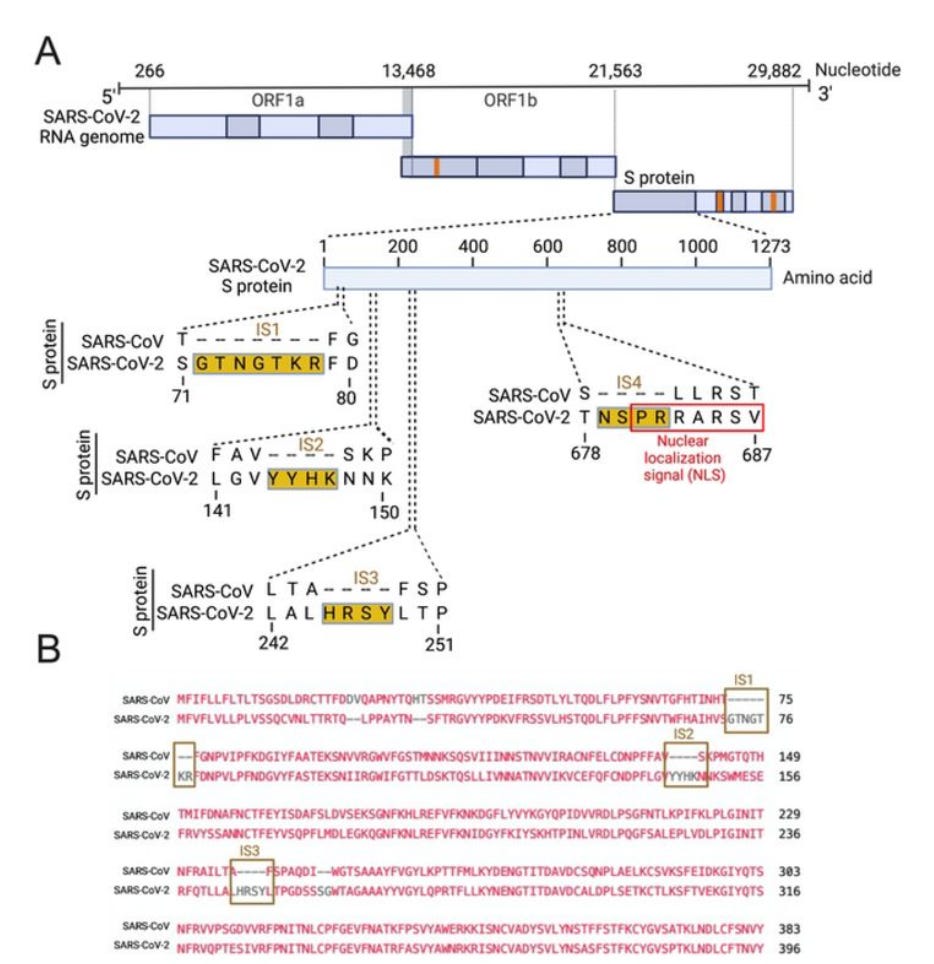
https://www.biorxiv.org/content/10.1101/2022.09.27.509633v1
The implications of this are vast, however I feel it's at least a warning signal that reverse transcription may actually be a plausible concern, in relation to the mRNA LNP based platforms (I have other evidence, however it will not be covered here at this time)
Amendment: I believe this sequence means the spike protein ends up in the nucleus. I don’t actually think that has implications for reverse transcription after further thought, as I think the mRNA may have to get there for that to be a possibility (or perhaps a process duplicates it in the cytoplasm, and then it ends up in the nucleus. I do not know the specifics of reverse transcription to say). What it may ACTUALLY hold implications for, is the retracted V(D)J recombination paper that found spike protein can damage DNA repair and V(D)J recombination in developing immune cells
https://www.mdpi.com/1999-4915/13/10/2056/htm
However what it doesn't cover, is that it also corroborated the findings of the Indian preprint that found HIV homology. They have drawn their brackets at different spots in each paper, because in one they're talking about a specific theoretical function, while calling only the added acids the "insert". In the other paper, they are talking about amino acids that don't appear in the SARS consensues sequence (added), plus others that have changed (altered). It's a difference in semantics for what you want to qualify as an "insert". The actual sequence, is identical, and it is also identical with another paper that shows more information about these structures, and with the original Ref Seq. on the NIH website. First, the Indian preprint. Insert 4 is the insert in question. Only NSPR has been fully inserted comparatively to SARS 1 (hence the first paper calling NSPR an insert) however, the rest of the HIV homolgy was made by altering already present amino acids. In other words, NSPR was added, and acids around it were changed. One paper calls NSPR the insert and the other calls the entire QTNSPRRA the "insert" since the QT and RA were changed, and that made the entire sequence homlogous to HIV 1 GAG
https://medicalveritas.org/wp-content/uploads/2020/02/Pradham-et-al-Coronavirus-HIV-paper.pdf


And now, the third preprint that goes into further detail, and illustrates how there is also homolgoy of the same segment + a portion that was already there from SARS 1, that when read together equal a SEB homologous region in the reverse reading direction
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC7263503/pdf/nihpp-2020.05.21.109272.pdf


I know this, because of the “R685” for the SEB sequence, and the “A684” previously discussed in the highlighted section. Those, are the end of the PRRAR furin cleavage site. Going backwards to the first E we see, gets us the following sequence:
ECDIPIGAGICASYQTQTNSPRRAR
which is the full reverse reading version. There is a front reading version I haven’t covered, but is also described in the highlighted section
This region is for one, clearly visible in the Ref. seq. of Wuhan H u 1 (the version used in the "vaccinations") meaning this fragment is likely still present in the shots, barring documentation stating otherwise (I have never seen such proof or documentation)
https://www.genome.jp/dbget-bin/www_bget?refseq:NC_045512

And is NOT the same in a random Omi varient I chose (indicating natural attenuation. this natural attenuation is also a possible indicator of manmade manipulation, as the original version was too virulent, and has been pressured out):
https://www.ncbi.nlm.nih.gov/nuccore/OM570283.1
ECDIPIGAGICASYQTQTKSHRRAR

The furin cleavage site has obviously mutated and probably attenuated, as well as the N that was before it, as long as those amino acids are not interchangable (amino acid protperties are determined by R group, so some may still function the same or at a reduced capacity if swapped with another amino acid with an identical or similar R group, brushing up needed)